麦子学院 2017-04-24 21:08
Python标准库学习之collections模块详解
回复:0 查看:3588
这个模块提供几个非常有用的Python
容器类型
1.容器
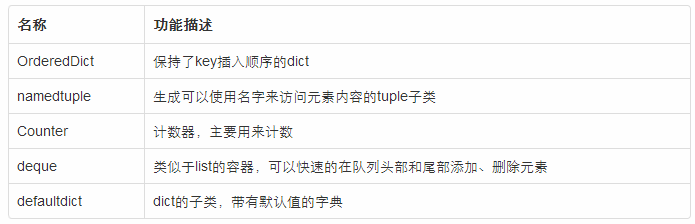
2.OrderedDict
OrderedDict
类似于正常的词典,只是它记住了元素插入的顺序,当迭代它时,返回它会根据插入的顺序返回。
·
和正常字典相比
,
它是
”
有序
”
的
(
插入的顺序
)
。
from collections import OrderedDict
dict1 = dict() #
普通字典
dict1['apple'] = 2
dict1['banana'] = 1
dict1['orange'] = 3
dict2 = OrderedDict() #
有序字典
dict2['apple'] = 2
dict2['banana'] = 1
dict2['orange'] = 3
for key,
value
in dict1.items():
print 'key:', key, ' value:',
value
for key,
value
in dict2.items():
print 'key:', key, ' value:',
value
# ----
输出结果
-----
#
普通字典
key: orange value: 3key: apple value: 2key: banana value: 1
#
有序字典
key: apple value: 2key: banana value: 1key: orange value: 3
·
如果重写已经存在的
key
,原始顺序保持不变,如果删除一个元素再重新插入,那么它会在末尾。
from collections
import OrderedDict
dict2 = OrderedDict()
dict2['apple'] = 2
dict2['banana'] = 1
dict2['orange'] = 3
#
直接重写
apple
的值
,
顺序不变
dict2['apple'] = 0
#
删除在重新写入
banana,
顺序改变
dict2.pop('banana')
dict2['banana'] = 1
print dict2
# ----
输出结果
-----
OrderedDict([('apple', 0), ('orange', 3), ('banana', 1)])
·
可以使用排序函数,将普通字典变成
OrderedDict
。
from collections
import OrderedDict
d = {'banana': 3, 'apple': 4, 'pear': 1, 'orange': 2}
order_d = OrderedDict(sorted(d.items(), key=lambda t: t[1]))
for key,
value
in order_d.items():
print 'key:', key, ' value:',
value
# ----
输出结果
-----key: pear value: 1key: orange value: 2key: banana value: 3key: apple value: 4
3.namedtuple
namedtuple
就是命名的
tuple
,一般情况下的
tuple
是这样的
(item1, item2, item3,…)
,所有的
item
都只能通过
index
访问,没有明确的称呼,而
namedtuple
就是事先把这些
item
命名,以后可以方便访问。
from collections
import namedtuple
#
定义一个
namedtuple
类型
User
,并包含
name
,
sex
和
age
属性。
User = namedtuple('User', ['name', 'sex', 'age'])
#
创建一个
User
对象
user1 = User(name='name1', sex='male', age=18)
#
也可以通过一个
list
来创建一个
User
对象,这里注意需要使用
"_make"
方法
user2 = User._make(['name2', 'male', 21])
print 'user1:', user1
#
使用点号获取属性
print 'name:', user1.name, ' sex:', user1.sex, ' age:', user1.age
#
将
User
对象转换成字典,注意要使用
"_asdict"
print 'user1._asdict():', user1._asdict()
#
字典转换成
namedtuple
name_dict = {'name': 'name3', 'sex': 'male', 'age': 20}
print 'dict2namedtuple:', User(**name_dict)
#
修改对象属性,注意要使用
"_replace"
方法
print 'replace:', user1._replace(age=22)
#
----
输出结果
-----user1:
User(name='name1', sex='male', age=18)
name:
name1
sex:
male
age:
18user1._asdict():
OrderedDict([('name', 'name1'), ('sex', 'male'), ('age', 18)])
dict2namedtuple:
User(name='name3', sex='male', age=20)
replace:
User(name='name1', sex='male', age=22)
4.Counter
Counter
类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为
key
,其计数作为
value
。
· Counter
创建有如下几种方法
from collections
import Counter
print Counter('aabbcccd') #
从一个可
iterable
对象(
list
、
tuple
、
dict
、字符串等)创建
print Counter(['a', 'a', 'c']) #
从一个可
iterable
对象(
list
、
tuple
、
dict
、字符串等)创建
print Counter({'a': 4, 'b': 2}) #
从一个字典对象创建
print Counter(a=4, b=2) #
从一组键值对创建
# ----
输出结果
-----
Counter({'c': 3, 'a': 2, 'b': 2, 'd': 1})
Counter({'a': 2, 'c': 1})
Counter({'a': 4, 'b': 2})
Counter({'a': 4, 'b': 2})
·
获取元素的计数时和
dict
类似
,
但是这里的
key
不存在时返回
0
,而不是
KeyError
>>> c = Counter("acda")>>> c["a"]2>>> c["h"]0
·
可以使用
update
和
subtract
对计数器进行更新
(
增加和减少
)
from collections
import Counter
c = Counter('aaabbc')
print 'c:', c
c.update("abc")print 'c.update("abc"):', c #
用另一个
iterable
对象
update
也可传入一个
Counter
对象
c.subtract("abc")print 'c.subtract("abc"):', c #
用另一个
iterable
对象
subtract
也可传入一个
Counter
对象
# ----
输出结果
-----
c: Counter({'a': 3, 'b': 2, 'c': 1})
c.
update("abc"): Counter({'a': 4, 'b': 3, 'c': 2})
c.subtract("abc"): Counter({'a': 3, 'b': 2, 'c': 1})
·
返回计数次数
top n
的元素
from collections
import Counter
c = Counter('aaaabbcccddeeffg')
print c.most_common(3)
# ----
输出结果
-----
[('a', 4), ('c', 3), ('b', 2)]
· Counter
还支持几个为数不多的数学运算
+
、
-
、
&
、
|
from collections
import Counter
a = Counter(a=3, b=1)
b = Counter(a=1, b=1)
print 'a+b:', a + b #
加法
,
计数相加
print 'a-b:', a - b #
减法
,
计数相减
print 'b-a:', b - a #
只保留正计数
print 'a&b:', a & b #
交集
print 'a|b:', a | b #
并集
# ----
输出结果
-----
a+b: Counter({'a': 4, 'b': 2})
a-b: Counter({'a': 2})
b-a: Counter()
a&b: Counter({'a': 1, 'b': 1})
a|b: Counter({'a': 3, 'b': 1})
5.deque
deque
就是双端队列,是一种具有队列和栈的性质的数据结构,适合于在两端添加和删除,类似与序列的容器
·
常用方法
from collections
import deque
d = deque([]) #
创建一个空的双队列
d.append(item) #
在
d
的右边
(
末尾
)
添加项目
item
d.appendleft(item) #
从
d
的左边
(
开始
)
添加项目
item
d.clear() #
清空队列
,
也就是删除
d
中的所有项目
d.extend(iterable) #
在
d
的右边
(
末尾
)
添加
iterable
中的所有项目
d.extendleft(item) #
在
d
的左边
(
开始
)
添加
item
中的所有项目
d.pop() #
删除并返回
d
中的最后一个
(
最右边的
)
项目。如果
d
为空,则引发
IndexError
d.popleft() #
删除并返回
d
中的第一个
(
最左边的
)
项目。如果
d
为空,则引发
IndexError
d.rotate(n=1)#
将
d
向右旋转
n
步
(
如果
n<0,
则向左旋转
)
d.count(n) #
在队列中统计元素的个数,
n
表示统计的元素
d.remove(n) #
从队列中删除指定的值
d.reverse() #
翻转队列
6.defaultdict
使用dict
时,如果引用的
Key
不存在,就会抛出
KeyError
。如果希望key
不存在时,返回一个默认值,就可以用
defaultdict
·
比如要统计字符串中每个单词的出现频率
from collections
import defaultdict
s = 'ilikepython'
#
使用普通字典
frequencies = {}
for
each in s:
frequencies[
each] += 1
#
使用普通字典
frequencie = defaultdict(
int)
for
each in s:
frequencie[
each] += 1
第一段代码中会抛出一个
KeyError
的异常,
而使用
defaultdict
则不会。
defaultdict
也可以接受一个函数作为参数来初始化
:
>>> from collections import defaultdict>>> d = defaultdict(lambda : 0)>>> d['0']0
来源:
博客园